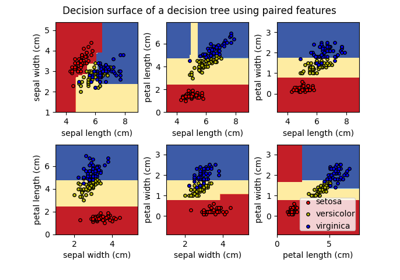
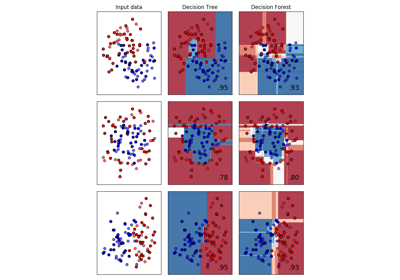
koho.sklearn.DecisionForestClassifier¶
-
class
koho.sklearn.DecisionForestClassifier(n_estimators=100, bootstrap=False, oob_score=False, class_balance='balanced', max_depth=3, max_features='auto', max_thresholds=None, random_state=None, n_jobs=None)[source]¶ A decision forest classifier.
- Parameters
- n_estimatorsinteger, optional (default=10)
The number of decision trees in the forest.
- bootstrapboolean, optional (default=True)
Whether bootstrap samples are used when building trees. Out-of-bag samples are used to estimate the generalization accuracy.
- oob_scorebool, optional (default=False)
Whether to use out-of-bag samples to estimate the generalization accuracy.
- class_balancestring ‘balanced’ or None, optional (default=’balanced’)
Weighting of the classes.
If ‘balanced’, then the values of y are used to automatically adjust class weights inversely proportional to class frequencies in the input data.
If None, all classes are supposed to have weight one.
- max_depthinteger or None, optional (default=3)
The maximum depth of the tree.
If None, the depth of the tree is expanded until all leaves are pure or no further impurity improvement can be achieved.
- max_featuresint, float, string or None, optional (default=None)
The number of random features to consider when looking for the best split at each node.
If int, then consider max_features features.
If float, then max_features is a percentage and int(max_features * n_features) features are considered.
If “auto”, then max_features=sqrt(n_features).
If “sqrt”, then max_features=sqrt(n_features).
If “log2”, then max_features=log2(n_features).
If None, then max_features=n_features considering all features in random order.
Note: the search for a split does not stop until at least one valid partition of the node samples is found up to the point that all features have been considered, even if it requires to effectively inspect more than
max_featuresfeatures.Decision Tree:
max_features=Noneandmax_thresholds=NoneRandom Tree:
max_features<n_featuresandmax_thresholds=None- max_thresholds1 or None, optional (default=None)
The number of random thresholds to consider when looking for the best split at each node.
If 1, then consider 1 random threshold, based on the Extreme Randomized Tree formulation.
If None, then all thresholds, based on the mid-point of the node samples, are considered.
Extreme Randomized Trees (ET):
max_thresholds=1Totally Randomized Trees:
max_features=1andmax_thresholds=1, very similar to Perfect Random Trees (PERT).- random_stateint or None, optional (default=None)
A random state to control the pseudo number generation and repetitiveness of fit().
If int, random_state is the seed used by the random number generator;
If None, the random number generator is seeded with the current system time.
- n_jobsinteger, optional (default=None)
The number of jobs to run in parallel for both fit and predict.
None means 1.
If -1, then the number of jobs is set to the number of cores.
- Attributes
- classes_array, shape = [n_classes]
The classes labels.
- n_classes_int
The number of classes.
- n_features_int
The number of features.
- estimators_list of tree objects from DecisionTreeClassifier
The collection of the underlying sub-estimators.
feature_importances_array, shape = [n_features]Get feature importances from the decision forest.
- oob_score_float
Score of the training dataset obtained using an out-of-bag estimate.
-
__init__(self, n_estimators=100, bootstrap=False, oob_score=False, class_balance='balanced', max_depth=3, max_features='auto', max_thresholds=None, random_state=None, n_jobs=None)[source]¶ Create a new decision forest classifier and initialize it with hyperparameters.
-
feature_importances_¶ Get feature importances from the decision forest.
-
fit(self, X, y)[source]¶ Build a decision forest classifier based on decision tree classifiers from the training data.
- Parameters
- Xarray, shape = [n_samples, n_features]
The training input samples.
- yarray, shape = [n_samples]
The target class labels corresponding to the training input samples.
- Returns
- selfobject
Returns self.
-
get_params(self, deep=True)¶ Get parameters for this estimator.
- Parameters
- deepboolean, optional
If True, will return the parameters for this estimator and contained subobjects that are estimators.
- Returns
- paramsmapping of string to any
Parameter names mapped to their values.
-
predict(self, X)[source]¶ Predict classes for the test data using soft voting.
- Parameters
- Xarray, shape = [n_samples, n_features]
The test input samples.
- Returns
- yarray, shape = [n_samples]
The predicted classes for the test input samples.
-
predict_proba(self, X)[source]¶ Predict classes probabilities for the test data.
- Parameters
- Xarray, shape = [n_samples, n_features]
The test input samples.
- Returns
- parray, shape = [n_samples, n_classes]
The predicted classes probablities for the test input samples.
-
score(self, X, y, sample_weight=None)¶ Returns the mean accuracy on the given test data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
- Parameters
- Xarray-like, shape = (n_samples, n_features)
Test samples.
- yarray-like, shape = (n_samples) or (n_samples, n_outputs)
True labels for X.
- sample_weightarray-like, shape = [n_samples], optional
Sample weights.
- Returns
- scorefloat
Mean accuracy of self.predict(X) wrt. y.
-
set_params(self, **params)¶ Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as pipelines). The latter have parameters of the form
<component>__<parameter>so that it’s possible to update each component of a nested object.- Returns
- self