User Guide¶
koho (Hawaiian word for ‘to estimate’) is a Decision Forest C++ library with a scikit-learn compatible Python interface.
Classification
Numerical (dense) data
Missing values (Not Missing At Random (NMAR))
Class balancing
Multi-Class
Multi-Output (single model)
Build order: depth first
Impurity criteria: gini
n Decision Trees with soft voting
Split a. features: best over k (incl. all) random features
Split b. thresholds: 1 random or all thresholds
Stop criteria: max depth, (pure, no improvement)
Bagging (Bootstrap AGGregatING) with out-of-bag estimates
Important Features
Export Graph
Python¶
We provide a scikit-learn compatible Python interface.
Classification¶
The koho library provides the following classifiers:
DecisionTreeClassifier
DecisionForestClassifier
We use the iris dataset provided by scikit-learn for illustration purposes.
>>> from sklearn.datasets import load_iris
>>> iris = load_iris()
>>> X, y = iris.data, iris.target
>>> from koho.sklearn import DecisionTreeClassifier, DecisionForestClassifier
>>> clf = DecisionForestClassifier(random_state=0)
max_features=None and max_thresholds=Nonemax_features<n_features and max_thresholds=Nonemax_thresholds=1max_features=1 and max_thresholds=1 very similar to Perfect Random Trees (PERT).Training
>>> clf.fit(X, y)
DecisionForestClassifier(bootstrap=False, class_balance='balanced',
max_depth=3, max_features='auto', max_thresholds=None,
missing_values=None, n_estimators=100, n_jobs=None,
oob_score=False, random_state=0)
Feature Importances
>>> feature_importances = clf.feature_importances_
>>> print(feature_importances)
[0.09045256 0.00816573 0.38807981 0.5133019]
Visualize Trees
Export a tree in graphviz format and visualize it using graphviz:
$: conda install python-graphviz
>>> import graphviz
>>> tree_idx = 0
>>> dot_data = clf.estimators_[tree_idx].export_graphviz(
... feature_names=iris.feature_names,
... class_names=iris.target_names,
... rotate=True)
>>> graph = graphviz.Source(dot_data)
>>> graph
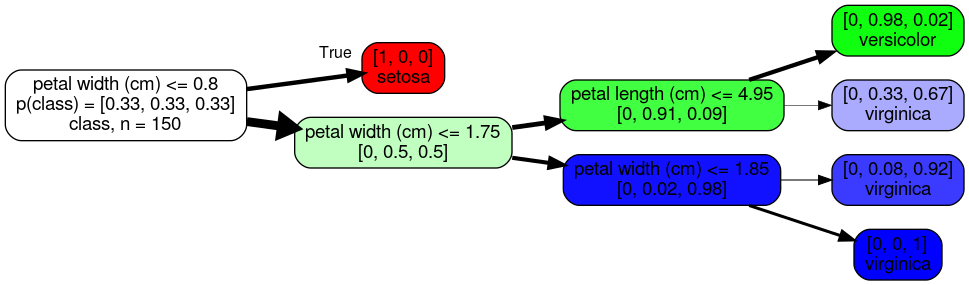
Convert the tree to different file formats (e.g. pdf, png):
>>> graph.render("iris", format='pdf')
iris.pdf
Export a tree in a compact textual format:
>>> t = clf.estimators_[tree_idx].export_text()
>>> print(t)
0 X[3]<=0.8 [50, 50, 50]; 0->1; 0->2; 1 [50, 0, 0]; 2 X[3]<=1.75 [0, 50, 50]; 2->3; 2->6; 3 X[2]<=4.95 [0, 49, 5]; 3->4; 3->5; 4 [0, 47, 1]; 5 [0, 2, 4]; 6 X[3]<=1.85 [0, 1, 45]; 6->7; 6->8; 7 [0, 1, 11]; 8 [0, 0, 34];
Persistence
>>> import pickle
>>> with open("clf.pkl", "wb") as f:
... pickle.dump(clf, f)
>>> with open("clf.pkl", "rb") as f:
... clf2 = pickle.load(f)
Classification
>>> c = clf2.predict(X)
>>> print(c)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
>>> cp = clf2.predict_proba(X)
>>> print(cp)
[[1. 0. 0. ]
[1. 0. 0. ]
[1. 0. 0. ]
...
[0. 0.01935722 0.98064278]
[0. 0.01935722 0.98064278]
[0. 0.09155897 0.90844103]]
Testing
>>> score = clf2.score(X, y)
>>> print("Score: %f" % score)
Score: 0.966667
scikit-learn’s ecosystem
Pipeline
>>> from sklearn.pipeline import make_pipeline
>>> pipe = make_pipeline(DecisionForestClassifier(random_state=0))
>>> pipe.fit(X, y)
>>> pipe.predict(X)
>>> pipe.predict_proba(X)
>>> score = pipe.score(X, y)
>>> print("Score: %f" % score)
Score: 0.966667
Grid Search
>>> from sklearn.model_selection import GridSearchCV
>>> parameters = [{'n_estimators': [10, 20],
... 'bootstrap': [False, True],
... 'max_features': [None, 1],
... 'max_thresholds': [None, 1]}]
>>> grid_search = GridSearchCV(DecisionForestClassifier(random_state=0), parameters, iid=False)
>>> grid_search.fit(X, y)
>>> print(grid_search.best_params_)
{'bootstrap': False, 'max_features': None, 'max_thresholds': 1, 'n_estimators': 10}
>>> clf = DecisionForestClassifier(random_state=0)
>>> clf.set_params(**grid_search.best_params_)
>>> clf.fit(X, y)
>>> score = clf.score(X, y)
>>> print("Score: %f" % score)
Score: 0.966667
Parallel Processing (joblib + dask)
Install and setup dask:
$: conda install dask distributed
>>> from dask.distributed import Client
>>> client = Client()
>>> clf = DecisionForestClassifier(random_state=0)
>>> from sklearn.externals.joblib import parallel_backend
>>> with parallel_backend('dask', n_jobs=-1): # 'loky' when not using dask
... clf.fit(X, y)
... score = clf.score(X, y)
>>> print("Score: %f" % score)
Score: 0.966667
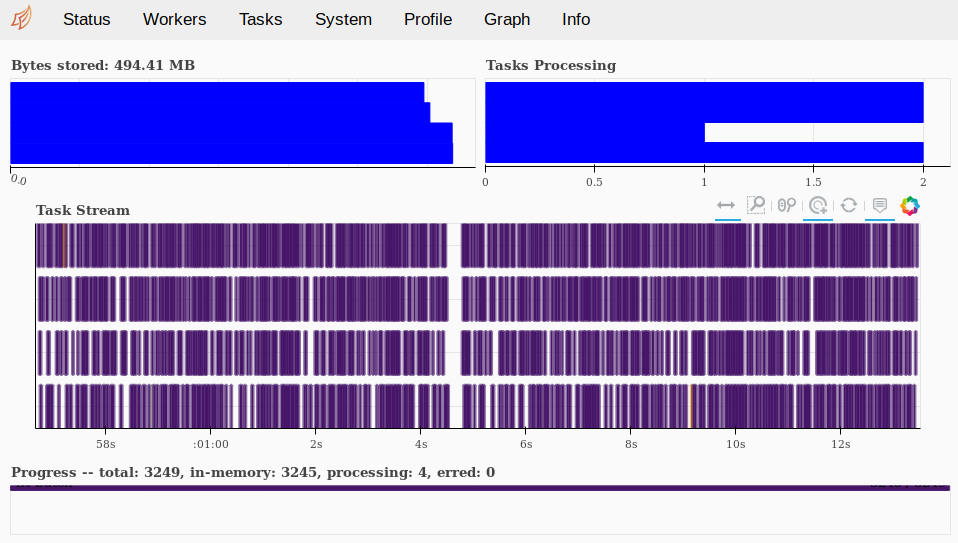
View progress with dask:
Firefox: http://localhost:8787/status
C++¶
We provide a C++ library.
Classification¶
The koho library provides the following classifiers:
DecisionTreeClassifier DecisionForestClassifier
We use a simple example for illustration purposes.
vector<vector<string>> classes = {{"0", "1", "2", "3", "4", "5", "6", "7"}};
vector<string> features = {"2^2", "2^1", "2^0"};
vector<double> X = {0, 0, 0,
0, 0, 1,
0, 1, 0,
0, 1, 1,
1, 0, 0,
1, 0, 1,
1, 1, 0,
1, 1, 1};
vector<long> y = {0,
1,
2,
3,
4,
5,
6,
7};
#include <decision_tree.h>
#include <decision_forest.h>
using namespace koho;
// Hyperparameters
string class_balance = "balanced";
long max_depth = 3;
long max_features = 0;
long max_thresholds = 0;
string missing_values = "None";
// Random Number Generator
long random_state = 0;
DecisionTreeClassifier dtc(classes, features,
class_balance, max_depth,
max_features, max_thresholds,
missing_values,
random_state);
Training
dfc.fit(X, y);
Feature Importances
vector<double> importances(features.size());
dtc.calculate_feature_importances(&importances[0]);
for (auto i: importances) cout << i << ' ';
// 0.571429 0.142857 0.285714
Visualize Trees
Export a tree in graphviz format and visualize it using graphviz:
$: sudo apt install graphviz
$: sudo apt install xdot
dtc.export_graphviz("simple_example", true);
$: xdot simple_example.gv
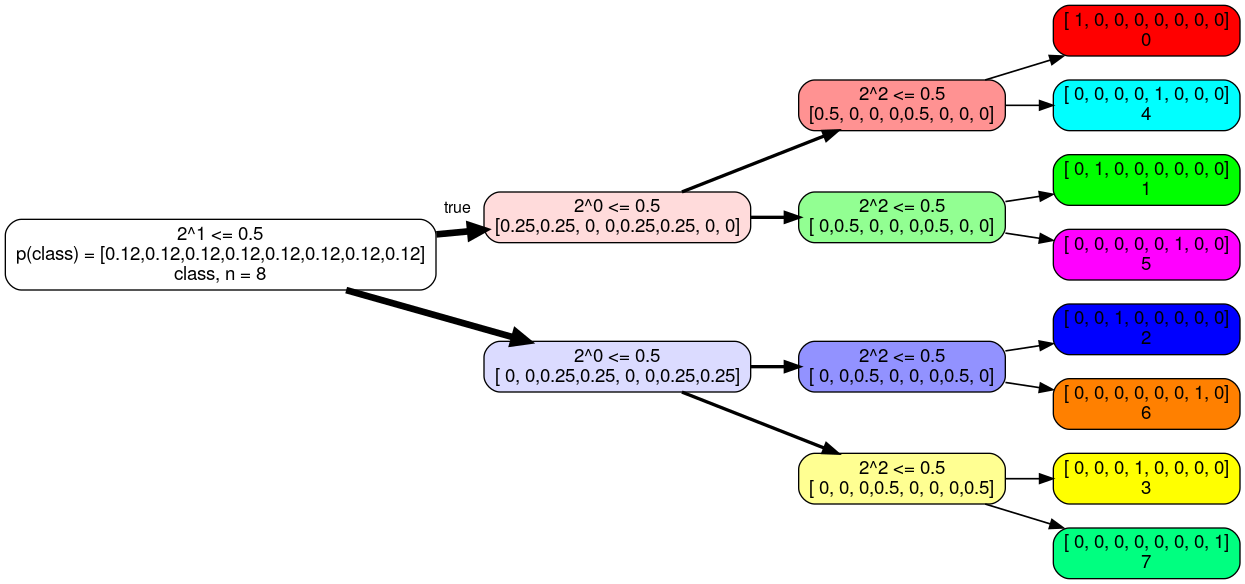
Convert the tree to different file formats (e.g. pdf, png):
$: dot -Tpdf simple_example.gv -o simple_example.pdf
Export a tree in a compact textual format:
cout << dtc.export_text() << endl;
// 0 X[1]<=0.5 [1, 1, 1, 1, 1, 1, 1, 1];
// 0->1; 0->8; 1 X[2]<=0.5 [1, 1, 0, 0, 1, 1, 0, 0];
// 1->2; 1->5; 2 X[0]<=0.5 [1, 0, 0, 0, 1, 0, 0, 0];
// 2->3; 2->4; 3 [1, 0, 0, 0, 0, 0, 0, 0]; 4 [0, 0, 0, 0, 1, 0, 0, 0]; 5 X[0]<=0.5 [0, 1, 0, 0, 0, 1, 0, 0];
// 5->6; 5->7; 6 [0, 1, 0, 0, 0, 0, 0, 0]; 7 [0, 0, 0, 0, 0, 1, 0, 0]; 8 X[2]<=0.5 [0, 0, 1, 1, 0, 0, 1, 1];
// 8->9; 8->12; 9 X[0]<=0.5 [0, 0, 1, 0, 0, 0, 1, 0];
// 9->10; 9->11; 10 [0, 0, 1, 0, 0, 0, 0, 0]; 11 [0, 0, 0, 0, 0, 0, 1, 0]; 12 X[0]<=0.5 [0, 0, 0, 1, 0, 0, 0, 1];
// 12->13; 12->14; 13 [0, 0, 0, 1, 0, 0, 0, 0]; 14 [0, 0, 0, 0, 0, 0, 0, 1];
Persistence
dtc.export_serialize("simple_example");
DecisionTreeClassifier dtc2 = DecisionTreeClassifier::import_deserialize("simple_example");
// simple_example.dtc
Classification
vector<long> c(n_samples, 0);
dtc2.predict(&X[0], n_samples, &c[0]);
for (auto i: c) cout << i << ' ';
// 0 1 2 3 4 5 6 7
Testing
double score = dtc2.score(&X[0], &y[0], n_samples);
cout << score
// 1.0
Tested Version¶
koho 1.1.0,
python 3.7.3,
cython 0.29.10,
gcc 7.4.0 C++ 17,
git 2.17.1,
conda 4.6.14,
pip 19.0.3,
numpy 1.16.4,
scipy 1.3.0,
scikit-learn 0.21.2,
python-graphviz 0.11,
jupyter 1.0.0,
tornado 5.1.1,
doxygen 1.8.13,
sphinx 2.1.2,
sphinx-gallery 0.4.0,
sphinx_rtd_theme 0.4.3,
matplotlib 3.1.0,
pillow 6.0.0,
pytest 4.6.3,
pytest-cov 2.7.1,
dask 2.0.0,
distributed 2.0.1